파이썬 기본 문법 공부하기
1. 기본 출력
print("하이 스파르타~")
2. 변수 선언
a="하이"
b="스파르타~"
print(a+b)즉, 파이썬은 JavaScript와 달리 변수 선언 시 let과 같은 명령어가 요구되지 않는다.
3. 리스트 선언 및 리스트에 요소 추가하기
fruit=["사과", "귤", "포도"]
print("이전 리스트: ", fruit)
what_i_want="감"
fruit.append(what_i_want) #요소 추가
print("이후 리스트: ", fruit)
4. 딕셔너리 선언 및 딕셔너리에 요소 추가하기
gd_info={"이름": "권지용", "나이": 33, "소속그룹": "BIGBANG"}
print("지드래곤의 이름은", gd_info["이름"], "입니다!")
#지드래곤 A형이더라??
gd_info["혈액형"]="A형"
print("지드래곤의 혈액형은", gd_info["혈액형"], "입니다!")
5. 함수 선언 및 호출
def sum(a, b): #매개변수로 a, b 2개를 받겠다!
return a+b #매개변수로 받은 a와 b의 합을 반환하겠다!
answer=sum(2, 3)
print(answer)
6. 조건문
def is_adult(age): #매개변수로 age 1개를 받겠다!
if age>20: #매개변수로 받은 age의 값이 20보다 크면
print("성인입니다!")
else: #20보다 크지 않으면
print("성인이 아닙니다!")
my_age=25
child_age=10
print("저는 ", end="")
is_adult(my_age)
print("저 아이는 ", end="")
is_adult(child_age)
7. 반복문
do_you_know_this_game=["딸기", "당근", "수박", "참외", "메론"]
for fruit in do_you_know_this_game:
print(fruit)
크롤링 기초
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')크롤링을 진행하기 전에 작성해야 하는 기본 코드는 위와 같고, 'soup' 변수로부터 select() 또는 select_one() 함수를 활용하여 크롤링을 진행한다.
data = request.get() 안의 url만 수정하며 웹 크롤링을 진행해나가면 된다.
크롤링은 아래에서 직접 해보면서 이해하도록 하겠다.
크롤링 연습해보기 - 네이버 영화의 현재 순위, 제목, 평점 출력해보기 (https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829)
1. 웹 페이지에서 '순위', '제목', '평점' 항목 검사
'순위'항목은
#old_content > table > tbody > tr:nth-child(2) > td:nth-child(1) > img
#old_content > table > tbody > tr:nth-child(3) > td:nth-child(1) > img와 같은 셀렉터를 가지고 있었고, '제목' 항목은
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a와 같은 셀렉터를 가지고 있었고, '평점' 항목은
#old_content > table > tbody > tr:nth-child(2) > td.point
#old_content > table > tbody > tr:nth-child(3) > td.point와 같은 셀렉터를 가지고 있었다.
즉, 이번 크롤링에서 select() 함수에서 매개변수로 사용해야 할 셀렉터 부분은
#old_content > table > tbody > tr임을 확인할 수 있는 것이다.
2. select_one() 함수로 각각의 데이터 크롤링
#### 순위 ####
#old_content > table > tbody > tr:nth-child(2) > td:nth-child(1) > img
#old_content > table > tbody > tr:nth-child(3) > td:nth-child(1) > img
#### 제목 ####
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
#### 평점 ####
#old_content > table > tbody > tr:nth-child(2) > td.point
#old_content > table > tbody > tr:nth-child(3) > td.point
movies=soup.select("#old_content > table > tbody > tr")
for movie in movies:
rank=movie.select_one("td:nth-child(1) > img") #순위 가져오기
title=movie.select_one("td.title > div > a") #제목 가져오기
star=movie.select_one("td.point") #평점 가져오기각각의 데이터들의 셀렉터의 차이점들을 확인하고 그 부분을 select_one() 함수의 매개변수로 사용하여 데이터를 가져온다. 그렇게 가져온 데이터를 출력해보면 다음과 같다.
3. 크롤링한 데이터 가공 및 출력
이제 가져온 데이터를 뽑아내야 한다. 위의 출력 결과와 같이 아직은 데이터가 지저분한 상태이다. 우선은 조건문을 활용하여 None값을 처리해주어야 할 것이고, 우리는 순위나 제목과 같은 숫자나 문자열의 데이터만을 추출해내길 원하므로 데이터를 가공해주어야 한다.
제목과 평점은 단순히 '.text' 코드를 활용하면 원하는 결과를 추출해낼 수 있다. 그렇지만 순위의 경우에는 img 태그의 'alt' 속성값을 원하기 때문에 좀 더 고민을 해봐야 했다. 하지만 어려울 것 없이 img 태그는 단순 딕셔너리와 비슷한 형태라고 생각하면 됐다.
다음은 데이터 가공 코드와 그에 대한 결과이다.
if rank is not None and title is not None and star is not None:
print(rank['alt'], title.text, star.text)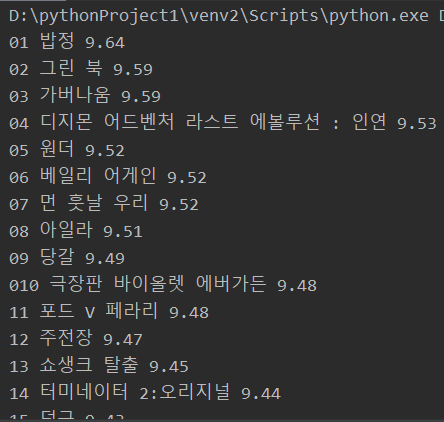
MongoDB와 Python 연결하기
from pymongo import MongoClient
import certifi
client = MongoClient('mongodb+srv://아이디가리기:비밀번호가리기@cluster0.1idhr.mongodb.net/디비가리기?retryWrites=true&w=majority', tlsCAFile=certifi.where())
db = client.dbsparta
doc = {
"name": "GD",
"age": 33
}
db.users.insert_one(doc)강의 자료대로 따라 쳤는데 안돼서 한 시간 동안 헤맸다 ㅠㅠ... ip 주소 때문에 그렇다는 사람들도 있었고, python 버전 문제도 있을 거라는 사람도 있었는데 import certifi 후, MongoClient()의 매개변수에 tlsCAFilt=certifi.where()를 추가해주고 해결되었다는 글을 보고 따라해보니 나도 해결되었다... 왜 그런지는 그 사람도 모른다고 한다.
[참고] 몽고db(mongoDB) atlas CERTIFICATE_VERIFY_FAILED 인증서 확인 실패 오류 (tistory.com)
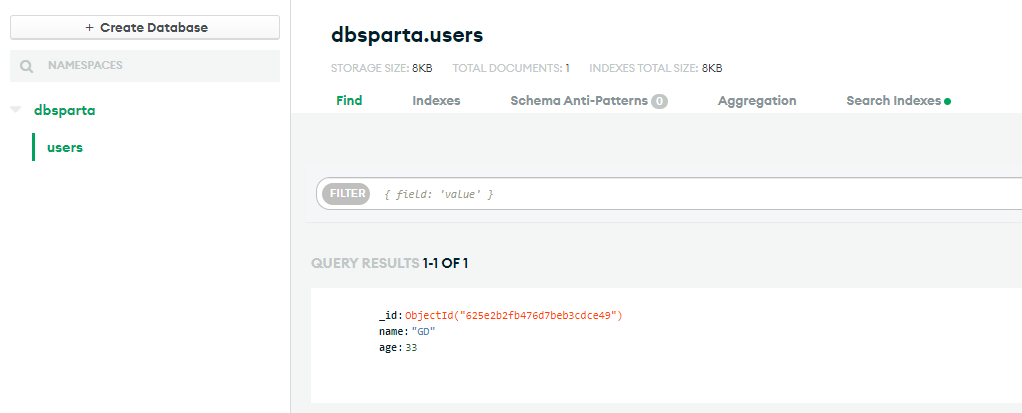
PyMongo로 DB 조작하기
1. 추가하기
db.users.insert_one({"name": "태양", "age": 33})
db.users.insert_one({"name": "탑", "age": 34})
db.users.insert_one({"name": "대성", "age": 32})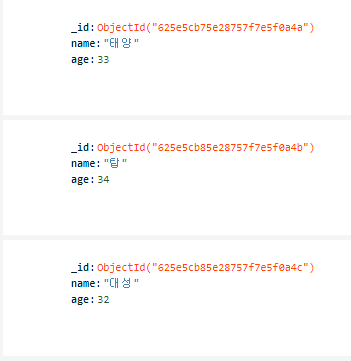
2. 전체 불러오기
all_users=list(db.users.find({}))
all_users_no_id=list(db.users.find({}, {"_id": False})) # id 빼고 출력하기 위함
for user in all_users:
print(user)
print()
for user in all_users_no_id:
print(user)
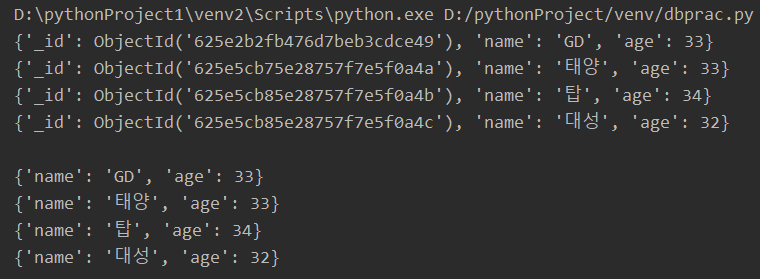
*** name: GD, age: 33 은 이전에 추가해뒀던 데이터임 ***
3. 부분 불러오기
gd=db.users.find_one({"name": "GD"})
print(gd)
4. 수정하기
db.users.update_one({'name':"GD"},{"$set":{"name":"지드래곤"}})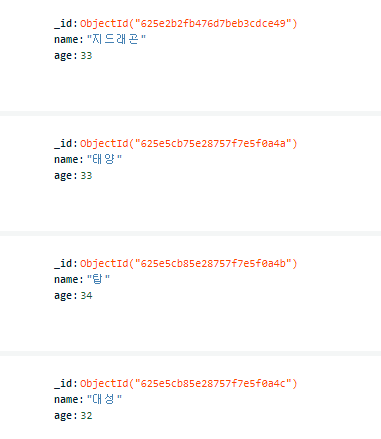
5. 삭제하기
db.users.delete_one({"name":"대성"})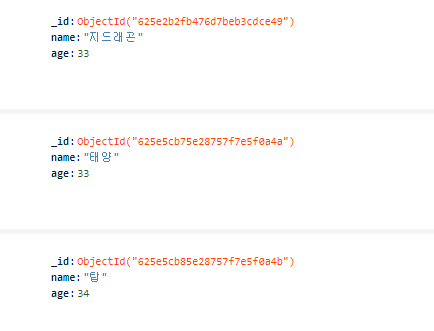
웹 크롤링 결과 저장하기
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import certifi
client = MongoClient('mongodb+srv://아이디가리기:비밀번호가리기@cluster0.1idhr.mongodb.net/디비가리기?retryWrites=true&w=majority', tlsCAFile=certifi.where())
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies=soup.select("#old_content > table > tbody > tr")
for movie in movies:
rank=movie.select_one("td:nth-child(1) > img") #순위 가져오기
title=movie.select_one("td.title > div > a") #제목 가져오기
star=movie.select_one("td.point") #평점 가져오기
if rank is not None and title is not None and star is not None:
doc={"rank": rank["alt"], "title":title.text, "star": star.text}
db.movies.insert_one(doc)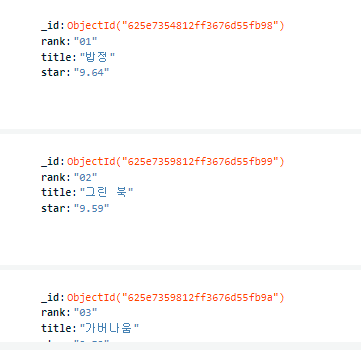
3번째 과제 - 지니뮤직 사이트 크롤링
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
### 순위 ###
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
#body-content > div.newest-list > div > table > tbody > tr:nth-child(2) > td.number
### 곡명 ###
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
#body-content > div.newest-list > div > table > tbody > tr:nth-child(2) > td.info > a.title.ellipsis
### 가수명 ###
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
#body-content > div.newest-list > div > table > tbody > tr:nth-child(2) > td.info > a.artist.ellipsis
top_100s=soup.select("#body-content > div.newest-list > div > table > tbody > tr")
for top_100 in top_100s:
rank=top_100.select_one("td.number")
song=top_100.select_one("td.info > a.title.ellipsis")
singer=top_100.select_one("td.info > a.artist.ellipsis")
print(rank.text.split(" ")[0].split("\n")[0], song.text.replace(" ", "").replace("\n", ""), singer.text)
흠... 15위 Peaches 앞에 19금이 붙어있는 것은 이모티콘일텐데 저걸 떼는 방법은 좀 더 생각해봤어야 될지도...?
2022.04.19 오늘을 돌아보며
오늘은 웹 크롤링과 크롤링한 결과를 DB에 저장하고 DB에 저장된 값을 갱신, 변경하는 방법에 대해 학습하였다. 아직 익숙하지 않아서 내가 썼던 코드를 복붙복붙 하고 있지만 익숙해지다보면 복붙보다 빨리 샥샥 쓸 수 있겠징...? 라고 생각중이다... ㅎㅎ 사람들이 크롤링 할 줄 알면 웹 거의 다 한거지! 라고 하던데 정말 그런거면 좋겠다 ㅠㅠ 아직까진 너무너무 재밌으니까!! 이대로만 하다 보면 진짜 내가 만들고 싶은 페이지란 페이지 대로 다 만들 수 있을 거 같다는 생각도 든다! (망상끝.)